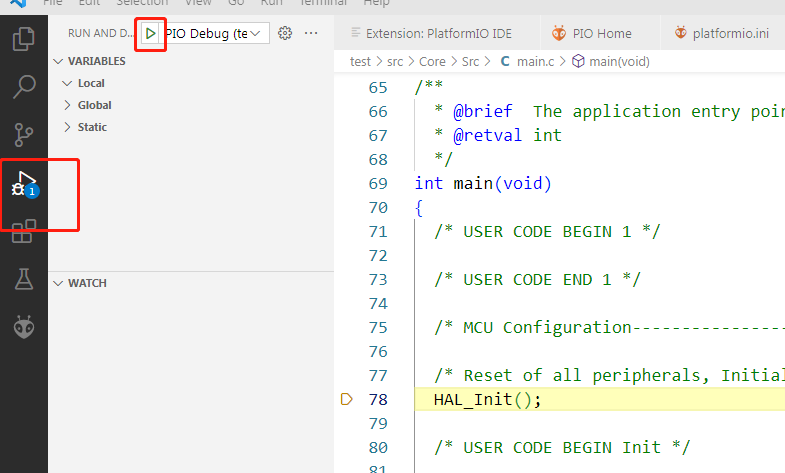
1.需要先给机器打上标记os_type: Linux或者os_type: Windows

2.代码请求获取数据:
先装一下相关的数据包 pip install pyzabbix
from pyzabbix import ZabbixAPI
import requests
import urllib3
import concurrent.futures
class ZabbixInfo():
def __init__(self, zabbix_server, zabbix_user, zabbix_password):
self.zabbix_server = zabbix_server
self.zabbix_user = zabbix_user
self.zabbix_password = zabbix_password
def get_hosts_disk_space_utilization(zabbix_info: ZabbixInfo):
host_disks_data_list = []
session = requests.Session()
# 忽略 SSL 验证的设置
session.verify = False
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
# 连接到 Zabbix API
zapi = ZabbixAPI(zabbix_info.zabbix_server, session=session)
zapi.login(zabbix_info.zabbix_user, zabbix_info.zabbix_password)
# 获取所有主机
hosts = zapi.host.get(output=['hostid', 'name'], selectInterfaces=[
'interfaceid', 'ip'], selectTags='extend',
selectParentTemplates=['templateid', 'name'])
# 多线程处理获取数据功能
with concurrent.futures.ThreadPoolExecutor() as executor:
# 提交任务并获取 Future 对象
futures = [executor.submit(get_host_disk_info, host, zapi)
for host in hosts]
# 收集所有返回值
for future in concurrent.futures.as_completed(futures):
host_disks_data_list.append(future.result())
zapi.user.logout()
return host_disks_data_list
def get_host_disk_info(host, zapi):
hostid = host['hostid']
# hostname = host['name']
host_ip = host['interfaces'][0]['ip']
host_disk_info_list = []
tags = host.get('tags', [])
os_type = 'Linux'
# 默认是 Linux,获取机器的类型
for tag in tags:
if tag['tag'] == 'os_type' and tag['value'] == 'Windows':
os_type = 'Windows'
break
diskset = set()
# 获取机器的磁盘列表
# lld_items = zapi.discoveryrule.get(
# hostids=hostid, search={'key_': 'vfs.fs.discovery'}, output=['itemid', 'name'])
# for lld_item in lld_items:
lld_results = zapi.item.get(hostids=hostid, output=[
'itemid', 'name', 'key_', 'lastvalue'])
for result in lld_results:
if 'vfs.fs.size' in result['key_']:
fsname = result['key_'].split('[')[1].split(',')[0]
# print(f"Host: {hostname} - OS: {os_type} - Filesystem: {fsname}")
# 提取文件系统名称
if 'Windows' == os_type or ('Linux' == os_type and str(fsname).startswith('/net') and str(fsname).endswith('/fs0')):
diskset.add(fsname)
# 多线程处理获取disk实际数据功能
host_data_dict = {}
with concurrent.futures.ThreadPoolExecutor() as executor:
# 提交任务并获取 Future 对象
futures = [executor.submit(
do_get_disk_info, host_disk_info_list, disk, hostid, zapi) for disk in diskset]
# 收集所有返回值
for future in concurrent.futures.as_completed(futures):
host_data_dict = {host_ip: future.result()}
return host_data_dict
def do_get_disk_info(host_disk_info_list, disk, hostid, zapi):
oid = 'vfs.fs.size[%s,pused]' % disk
items = zapi.item.get(hostids=hostid, search={'key_': oid}, output=[
'itemid', 'name', 'lastvalue'])
if items:
for item in items:
# print(f"Host: {hostname} ({os_type}) - Item: {item['name']} - Last Value: {item['lastvalue']}")
# print(
# f"Host: {hostname} ({os_type}) - {item['name']}: {item['lastvalue']}")
host_disk_info_list.append({item['name']: item['lastvalue']})
return host_disk_info_list
if __name__ == "__main__":
zabbix_info_list = []
zabbix_disk_info_list = []
zabbix_info_list.append(ZabbixInfo(
'http://xxxxxxxxxx', 'username', 'password'))
zabbix_info_list.append(ZabbixInfo(
'http://xxxxxxxxxxxxxx', 'username', 'password'))
for zabbix in zabbix_info_list:
zabbix_disk_info_list.append(get_hosts_disk_space_utilization(zabbix))
for item in zabbix_disk_info_list:
print(item)
最后的数据结构如下,这是我自己定义的,当然可以自己动代码进行修改